カウントソート
Merge Sortのようなアルゴリズムは、与えられた要素の並びをソートするのに 回程度の操作を必要とします。多くのプログラミング言語に標準で用意されている sort() 関数も、同様に の操作を行います。すると、「もっと速くソートする方法はないのか?」という疑問が自然に浮かんできますよね。
そんなとき、一つの答えになるのが線形時間、つまり でソートを行うアルゴリズムの代表例であるカウントソート(Counting Sort)です。カウントソートは、整数で値の範囲が比較的小さいデータをソートするときに特に有効で、要素数に対して非常に高速に動作します。
カウントソートの基本的な発想は、ある値を持つ要素がいくつあるかを数えるヒストグラムのような構造を使い、その情報を元に元の配列を昇順に並び替えるというものです。
例えば、配列 [7, 3, 5, 5, 1, 1, 6, 3, 4, 4, 3, 3, 7, 7, 1, 2, 5, 7, 4, 1, 7, 2, 1, 5, 5, 3, 1, 4, 8, 7] をソートしたいとき、値ごとに出現回数を数えたヒストグラムは [6, 2, 5, 4, 5, 1, 6, 1] のようになります(図のイメージと同様)。
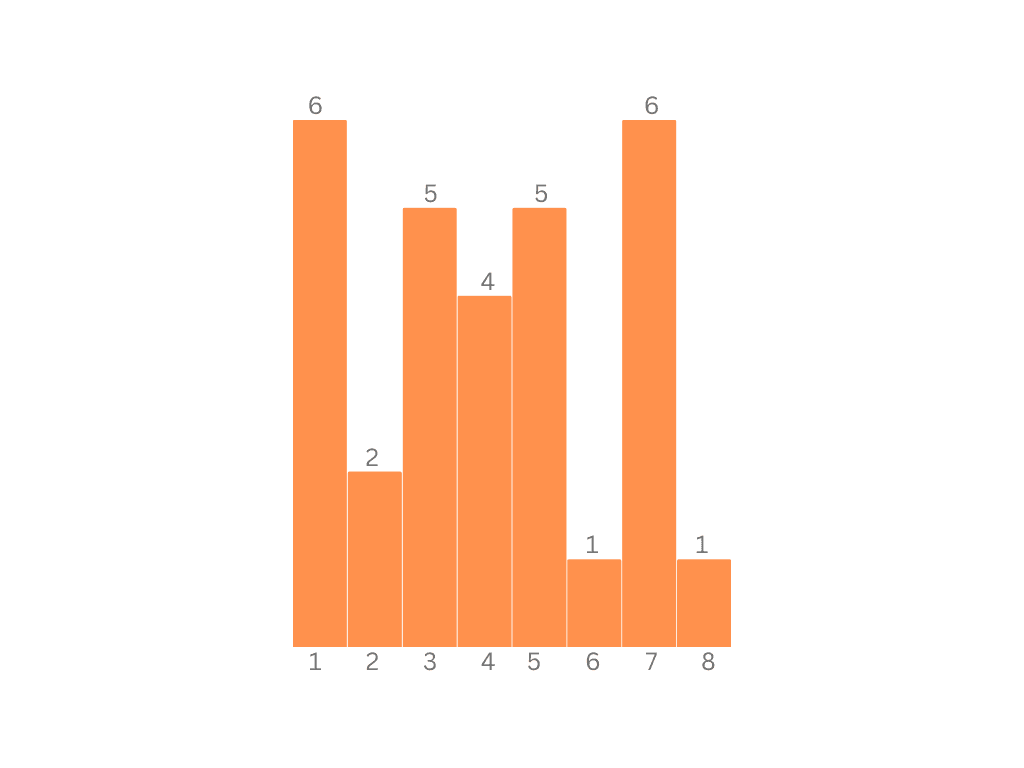
a = ...
bottom, top = min(a), max(a) + 1 # 範囲を確認する
hist = [0] * (top - bottom) # 0で初期化してカウントを保持するスペースを用意
for num in a: # 配列を順に走査する
hist[num - bottom] += 1 # 該当するヒストグラムの値を増やす
res = [] # 結果用配列を初期化する
for num in range(bottom, top): # 範囲を順に走査する
res += [num] * hist[num - bottom] # ヒストグラムで数えた回数だけ num を追加する最終的な結果として、配列は [1, 1, 1, 1, 1, 1, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 7, 7, 7, 7, 7, 7, 8] のように整列されます。
ただし、この方法は数値(しかも範囲が小さい整数)をソートする場合に有効です。より汎用的なアルゴリズムとして、Bubble Sort や Merge Sort などは「値同士が比較可能である」という条件だけで任意の要素をソートすることができます。
カウントソートの計算量は、最終的に となります。ここで、n は配列の要素数、r は値の範囲の大きさです。データが小さな範囲の整数である場合、Merge Sort などの アルゴリズムよりも高速に動作する可能性があります。
入力
1行目に整数 n (1 ≤ n ≤ ) が与えられます。
次の行に、n 個の整数 (-100 ≤ ≤ 100) がスペース区切りで与えられます。
出力
n 個の整数を小さい順に並べて、スペース区切りで出力してください。
例
Input | Output |
|---|---|
5 | -3 -1 2 5 10 |
Constraints
Time limit: 1.6 seconds
Memory limit: 512 MB
Output limit: 5 MB